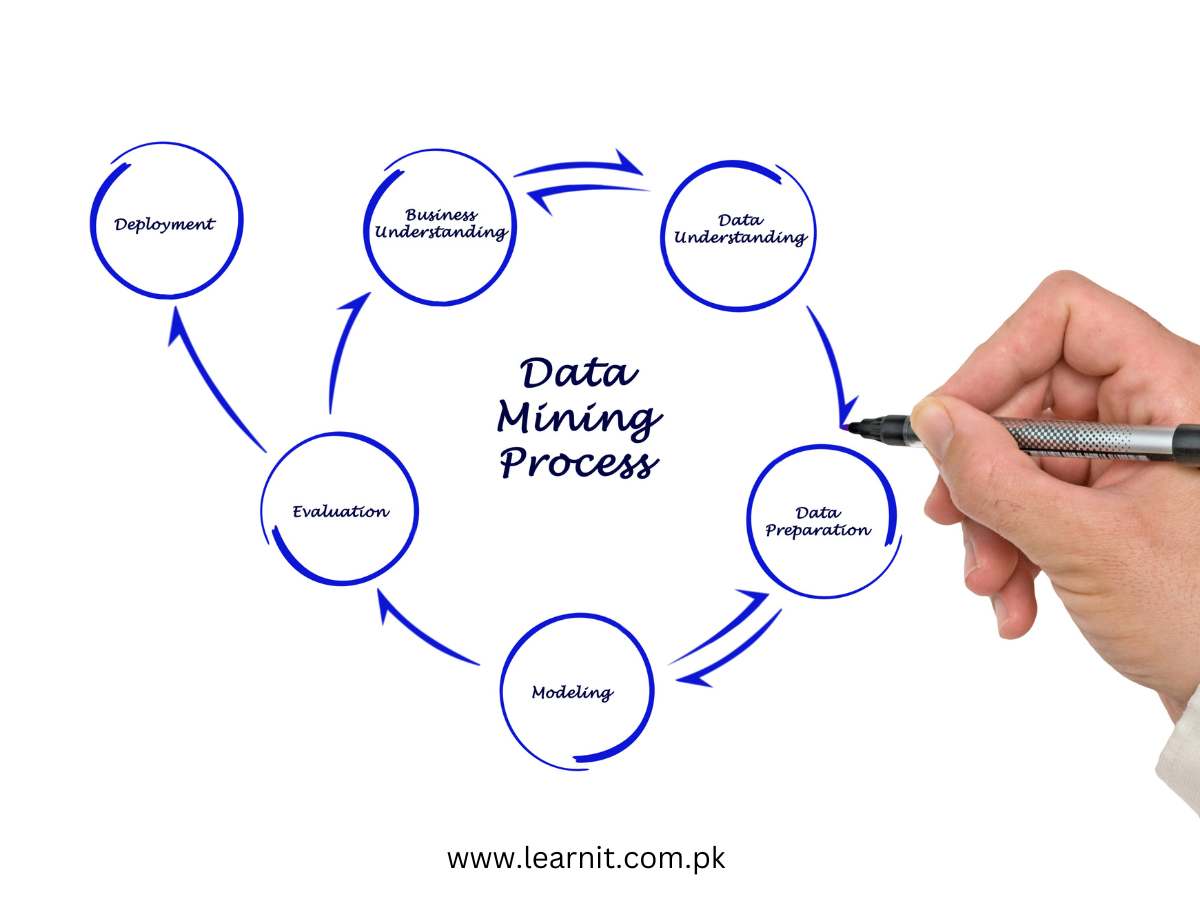
Knowledge Discovery Process in Data Mining:
The knowledge discovery process in data mining is a systematic approach that aims to extract valuable and actionable knowledge from large and complex datasets. This process involves several stages that transform raw data into meaningful insights, helping businesses make informed decisions and gain a competitive advantage.
1- Data Collection: Unearthing the Raw Material
The first step in the knowledge discovery process is data collection. Here, relevant data is gathered from various sources, such as databases, websites, customer feedback, or social media. To optimize the knowledge discovery process, ensure that data sources are reputable and relevant to the specific analysis.
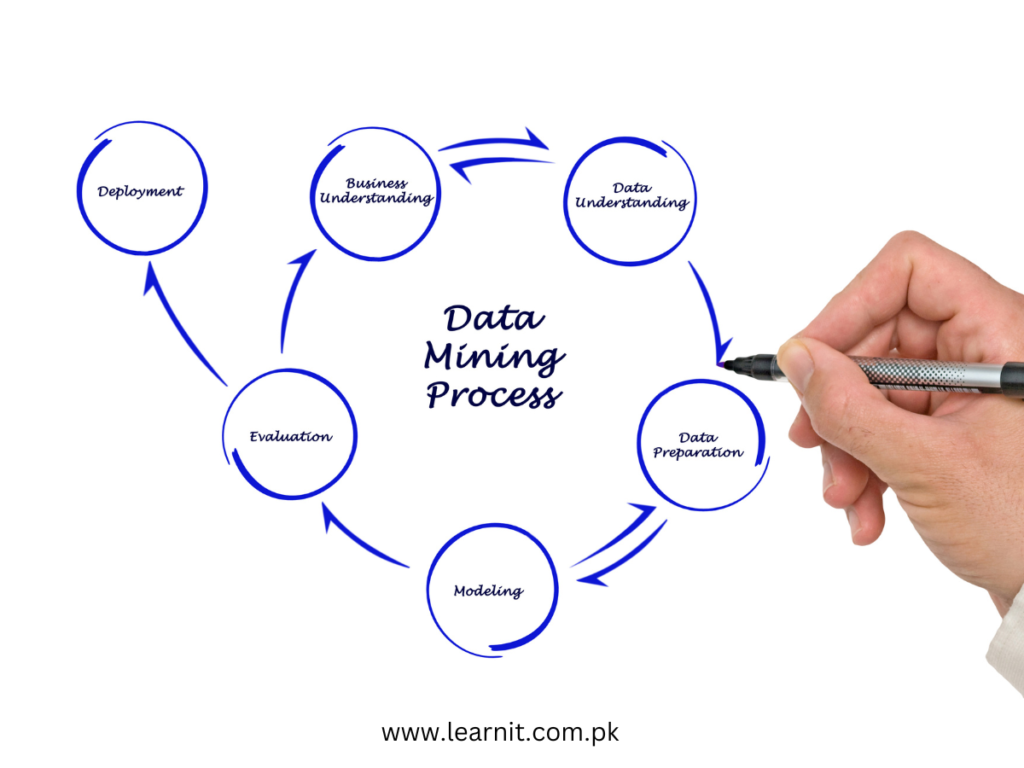
2- Data Cleaning: Polishing the Gem
Raw data often contains errors, missing values, and inconsistencies. Data cleaning involves removing duplicate records, correcting errors, and filling in missing data. A clean dataset is vital for accurate and reliable insights.
3- Data Integration: Piecing the Puzzle Together
Data from different sources may have varying formats and structures. Data integration involves merging and organizing data into a unified format, ensuring seamless analysis.
4- Data Transformation: Shaping the Stone
Data transformation prepares the dataset for analysis by converting it into a suitable format for data mining algorithms. This process may involve normalization, aggregation, or dimensionality reduction.
5- Data Reduction: Trimming the Excess
Large datasets can be computationally expensive and challenging to analyze. Data reduction techniques, such as sampling or feature selection, help reduce the dataset’s size while preserving critical information.
6- Data Mining: Unearthing the Precious Gems
The heart of the knowledge discovery process lies in data mining. Various algorithms, such as classification, clustering, association rule mining, and regression, are applied to identify patterns, relationships, and trends within the data.
7- Interpretation and Evaluation: Revealing the True Value
Once data mining is complete, the discovered patterns and insights need to be interpreted and evaluated. Domain experts analyze the results to determine their significance and practical value for decision-making.
8- Knowledge Representation: Crafting the Jewel
Representing the extracted knowledge in a meaningful and understandable manner is essential for effective communication with stakeholders and decision-makers. Visualizations, reports, and dashboards are commonly used for this purpose.
9- Knowledge Utilization: Putting the Gem to Good Use
The ultimate objective of the knowledge discovery process is to utilize the extracted insights to drive business decisions, process improvements, and strategic planning. Implementing the discovered knowledge leads to enhanced efficiency, better customer experiences, and increased business success.
10- Continuous Improvement: Polishing the Gem to Perfection
The knowledge discovery process is an iterative and ongoing endeavor. As new data becomes available or business requirements evolve, the process is revisited, refined, and improved to ensure continued value and relevance.
Example 1: Retail Customer Segmentation
In the retail industry, a large chain of stores wants to enhance its marketing efforts and customer experience by understanding its diverse customer base better. To achieve this, they decide to use the knowledge discovery process in data mining to segment their customers and tailor marketing strategies accordingly.
1. Data Collection:
The retail chain collects data from various sources, including point-of-sale transactions, loyalty program registrations, customer feedback surveys, and website interactions. This data includes purchase history, demographics, customer preferences, and other relevant information.
2. Data Cleaning:
The collected data is cleaned to remove any duplicates, correct errors, and fill in missing values. Data cleaning ensures the dataset’s integrity, making the subsequent analysis more accurate and reliable.
3. Data Integration:
Data from different sources, such as in-store transactions and online purchases, are integrated into a unified database to create a comprehensive customer profile.
4. Data Transformation:
The dataset is transformed to a suitable format for analysis. This may involve normalizing purchase values, converting categorical data into numerical representations, and standardizing variables.
5. Data Reduction:
Since the retail chain has a vast customer database, data reduction techniques are applied to manage computational complexity. Sampling is used to select a representative subset of customers for analysis while preserving key characteristics.
6. Data Mining:
Data mining algorithms, such as clustering and classification, are applied to segment the customers based on their purchasing behavior, preferences, and demographics. Clustering algorithms group similar customers together, while classification algorithms predict customer categories based on certain attributes.
7. Interpretation and Evaluation:
Domain experts analyze the results of the data mining process to interpret the customer segments and evaluate their significance. They identify distinct customer groups, such as frequent buyers, occasional shoppers, high spenders, and bargain hunters.
8. Knowledge Representation:
The customer segments and their characteristics are represented visually through charts and graphs. The retail chain creates a customer segmentation dashboard that showcases the different customer groups, their purchasing patterns, and other relevant insights.
9. Knowledge Utilization:
The retail chain utilizes the customer segmentation insights to tailor its marketing strategies. For instance, they create personalized promotions and offers for high spenders to encourage repeat purchases. They design loyalty programs targeted at occasional shoppers to increase their frequency of visits.
10. Continuous Improvement:
As the retail chain continues to collect new data and observes changes in customer behavior, the knowledge discovery process is revisited. They update their customer segmentation to reflect evolving trends, ensuring their marketing efforts remain relevant and effective.
Example 2: Predictive Maintenance in Manufacturing
A manufacturing company operates a large facility with various complex machinery and equipment. To optimize maintenance processes, reduce downtime, and improve operational efficiency, they decide to implement predictive maintenance using the knowledge discovery process in data mining.
1. Data Collection:
The manufacturing company collects data from sensors installed on machinery and equipment, including temperature, pressure, vibration, and other performance metrics. They also gather historical maintenance records, repair logs, and equipment specifications.
2. Data Cleaning:
The collected sensor data is cleaned to remove outliers, filter noise, and handle any missing or corrupted data. The integrity of the data is crucial for accurate predictive modeling.
3. Data Integration:
Data from various sensors and maintenance records are integrated into a central database to create a comprehensive dataset for analysis.
4. Data Transformation:
The dataset is transformed to prepare it for predictive modeling. Feature engineering techniques are applied to extract relevant features from the raw sensor data, such as calculating mean, standard deviation, or trend over time.
5. Data Reduction:
Since the manufacturing facility generates a vast amount of sensor data, data reduction techniques like sampling and feature selection are used to reduce the data’s size while retaining essential information.
6. Data Mining:
Data mining algorithms, such as regression and anomaly detection, are applied to analyze the transformed and reduced data. Regression models predict equipment failure based on sensor data patterns, while anomaly detection identifies deviations from normal behavior, indicating potential faults.
7. Interpretation and Evaluation:
Domain experts and maintenance engineers interpret the results of the data mining process. They evaluate the predictive models’ accuracy and interpret the identified anomalies to determine their significance and potential impact on equipment performance.
8. Knowledge Representation:
The predictive maintenance insights are represented through visualizations and reports. Dashboards are created to monitor the health of machinery and equipment in real-time, displaying predictions and potential anomalies.
9. Knowledge Utilization:
The manufacturing company utilizes the predictive maintenance insights to schedule maintenance proactively. Instead of relying on fixed maintenance schedules, they prioritize maintenance tasks based on predicted equipment failure or identified anomalies. This approach reduces unscheduled downtime and extends the lifespan of machinery.
10. Continuous Improvement:
As new sensor data is continuously collected, the knowledge discovery process is an ongoing effort. The predictive models are regularly updated and refined to reflect the changing behavior of machinery and equipment, ensuring that maintenance decisions remain accurate and effective.
Example 3: Credit Card Fraud Detection
A financial institution wants to enhance its fraud detection capabilities to safeguard its customers from credit card fraud. To achieve this, they decide to employ the knowledge discovery process in data mining to detect fraudulent transactions effectively.
1. Data Collection:
The financial institution collects transactional data from credit card transactions, including transaction amount, location, time, and other relevant details. They also gather historical data on past fraud cases and non-fraudulent transactions.
2. Data Cleaning:
The collected transactional data is cleaned to remove duplicate records, correct errors, and handle missing or incomplete data. Data cleaning ensures the accuracy and reliability of the dataset.
3. Data Integration:
Transactional data from different sources, such as online transactions and in-store purchases, are integrated into a single dataset for analysis.
4. Data Transformation:
The dataset is transformed to prepare it for fraud detection analysis. Feature engineering techniques are applied to extract relevant features, such as transaction frequency, spending patterns, and geographical information.
5. Data Reduction:
As the financial institution deals with a vast number of credit card transactions, data reduction techniques like sampling and feature selection are used to reduce the data’s size while retaining essential information.
6. Data Mining:
Data mining algorithms, such as anomaly detection and classification models, are applied to analyze the transformed and reduced data. Anomaly detection algorithms identify transactions that deviate significantly from normal behavior, potentially indicating fraudulent activities. Classification models classify transactions as either fraudulent or non-fraudulent based on features and patterns.
7. Interpretation and Evaluation:
Fraud analysts and domain experts interpret the results of the data mining process. They evaluate the accuracy and performance of the fraud detection models and interpret the identified anomalies to determine their relevance to potential fraud cases.
8. Knowledge Representation:
The fraud detection insights are represented through visualizations and reports. The financial institution creates a fraud detection dashboard that displays real-time alerts for potentially fraudulent transactions, allowing timely action.
9. Knowledge Utilization:
The financial institution utilizes the fraud detection insights to implement proactive fraud prevention measures. When a transaction is flagged as potentially fraudulent, the institution can trigger immediate investigation or notify the customer to verify the transaction’s legitimacy.
10. Continuous Improvement:
Fraud patterns and tactics continually evolve, necessitating an ongoing knowledge discovery process. The fraud detection models are regularly updated and refined to adapt to new fraud schemes and emerging threats, ensuring robust fraud prevention capabilities.
Example 4: Healthcare Diagnosis and Treatment Recommendation
A medical research institute aims to improve the accuracy of disease diagnosis and treatment recommendations. They decide to utilize the knowledge discovery process in data mining to analyze patient data and medical records.
1. Data Collection:
The medical research institute collects data from various sources, including electronic health records, diagnostic test results, medical imaging reports, and patient demographics. They also gather information from medical literature and research papers related to the diseases of interest.
2. Data Cleaning:
The collected patient data is cleaned to remove errors, inconsistencies, and missing values. Data cleaning ensures the reliability and quality of the dataset for accurate analysis.
3. Data Integration:
Patient data from different medical facilities and sources are integrated into a unified database, creating a comprehensive dataset for analysis.
4. Data Transformation:
The dataset is transformed to prepare it for analysis. Feature engineering techniques are applied to extract relevant features, such as patient vitals, laboratory test values, and medical history.
5. Data Reduction:
As medical data can be vast and complex, data reduction techniques like feature selection and dimensionality reduction are used to reduce the data’s complexity while retaining critical information.
6. Data Mining:
Data mining algorithms, such as decision trees, support vector machines, and neural networks, are applied to analyze the patient data. These algorithms can classify patients into different disease categories based on symptoms and medical test results and recommend appropriate treatments based on historical treatment outcomes.
7. Interpretation and Evaluation:
Medical experts and researchers interpret the results of the data mining process. They evaluate the performance of the disease diagnosis and treatment recommendation models and assess the relevance of the identified patterns and relationships.
8. Knowledge Representation:
The disease diagnosis and treatment recommendation insights are represented through visualizations and reports. The medical research institute creates decision support systems and medical dashboards that aid physicians in making informed decisions about patient care.
9. Knowledge Utilization:
The medical research institute utilizes the disease diagnosis and treatment recommendation insights to enhance medical practices. Physicians can access the decision support systems to receive personalized treatment recommendations for their patients based on their medical history and test results.
10. Continuous Improvement:
Medicine is a continually evolving field, and medical research is constantly generating new insights. The knowledge discovery process is ongoing, allowing the medical research institute to stay updated with the latest medical advancements and continuously improve the disease diagnosis and treatment recommendation models.
Example 5: E-commerce Product Recommendation
An e-commerce platform wants to improve its product recommendation system to enhance customer engagement and increase sales. They decide to apply the knowledge discovery process in data mining to analyze customer behavior and preferences.
1. Data Collection:
The e-commerce platform collects data from various sources, including user interactions, browsing history, purchase records, and customer feedback. They also gather product attributes and metadata.
2. Data Cleaning:
The collected data is cleaned to remove duplicate entries, correct errors, and handle missing values. Data cleaning ensures the accuracy and reliability of the dataset for effective analysis.
3. Data Integration:
Data from different sources, such as website activity logs and customer profiles, are integrated into a single database, creating a comprehensive dataset for analysis.
4. Data Transformation:
The dataset is transformed to prepare it for product recommendation analysis. Feature engineering techniques are applied to extract relevant features, such as customer preferences, product categories, and purchase frequencies.
5. Data Reduction:
As e-commerce platforms generate vast amounts of data, data reduction techniques like sampling and feature selection are used to reduce the data’s size while retaining essential information.
6. Data Mining:
Data mining algorithms, such as collaborative filtering, content-based filtering, and association rule mining, are applied to analyze the transformed and reduced data. These algorithms identify patterns in customer behavior and product associations.
7. Interpretation and Evaluation:
E-commerce analysts and marketers interpret the results of the data mining process. They evaluate the performance of the product recommendation models and interpret the identified patterns to understand customer preferences.
8. Knowledge Representation:
The product recommendation insights are represented through personalized product suggestions on the e-commerce platform. Customers receive tailored product recommendations based on their browsing history and past purchases.
9. Knowledge Utilization:
The e-commerce platform utilizes the product recommendation insights to improve customer engagement and increase sales. Personalized product recommendations are displayed prominently on the website, encouraging customers to discover new products and make additional purchases.
10. Continuous Improvement:
E-commerce trends and customer preferences are continuously evolving. The knowledge discovery process is ongoing, allowing the e-commerce platform to update and refine its product recommendation models to match changing customer behavior and preferences.
In conclusion, the knowledge discovery process in data mining involves a series of interconnected stages that transform raw data into valuable insights and knowledge. By following this systematic approach and applying data mining techniques, businesses can unearth hidden opportunities, address challenges, and make data-driven decisions to achieve success in the modern digital landscape.



